







GitHub tools collection
This is the current thread in the bug hunter community: how to find sensitive informations on GitHub. Understand how to find tokens/keys/passwords on the largest code database in the world in order to pwn a company and get massive rewards. Using tools or doing it manually, some very talented people like Th3G3nt3lman are real wizards when it comes to discover such treasures. Many tools are now available but since I wanted to learn Python for a long time, I jumped at the opportunity. In this article I’m going to present some scripts I wrote in PHP and Python to fit my needs.
Get the whole everything here: https://github.com/gwen001/github-search
All tools who contact the GitHub API require at least one token to be able to perform multiple queries.
The best way to deal with it is to create a single text file in the repository called .tokens with 1 token per line.
Then all scripts will load this file. (ps: the more token you have the better it is).
memo.txt
First of all you better understand how GitHub search engine works. Here is a very quick resume of the Official GitHub documentation.
term in filename: term in:file
term in path: term in:path
from a user: user:USERNAME
from an org: org:ORGNAME
in project: repo:USERNAME/REPOSITORY
filepath: term path:app/config (subdir included)
tagged language: language:python
filesize: size:>10000 (10kb)
filename: filename:config
extension: extension:py
string exclusion: hello NOT world
qualifier exclusion: cats stars:>10 -language:javascript
Use quotation marks for queries with whitespace
cats NOT "hello world"
...
git-history.py
This script performs regexps on all repositories located in a specified folder and subfolders. But more it searches in the history of the repositories, not only the current version of the files. All commits are checked!
usage: git-history.py [-h] [-p PATH] [-d DATE] [-c LENGTH] [-s SEARCH]
[-t THREADS]
optional arguments:
-h, --help show this help message and exit
-p PATH, --path PATH path to scan
-d DATE, --date DATE do no check commits prior this date, format: YYYY-MM-DD
-c LENGTH, --length LENGTH
only check in first n characters
-s SEARCH, --search SEARCH
term to search (regexp)
-t THREADS, --threads THREADS
max threads, default: 10
On big repositories (or folders who contain multiple repositories), this operation can take a while. To make it faster, you can customize the maximum threads used, set a date limit and a size option.
Examples:
git-history.py -p ~/repos -s "AKIA.*"
git-history.py -p ~/repos -s ~/.gf/aws-keys.json -d 2019-01-01 -c 1000000
Note that the regexps file (option -s) can be a single regexp or a file using the format of the nice tool gf by TomNomNom.

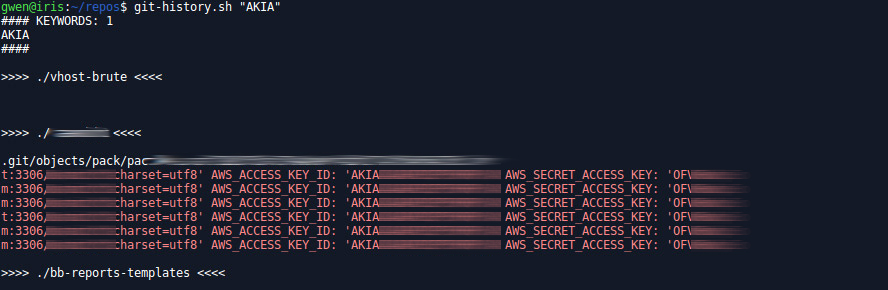
git-history.sh
Same same but different. Strongly inspired by TomNomNom onliner published on Twitter, this small bash script also looks for patterns in the history of Git repositories.
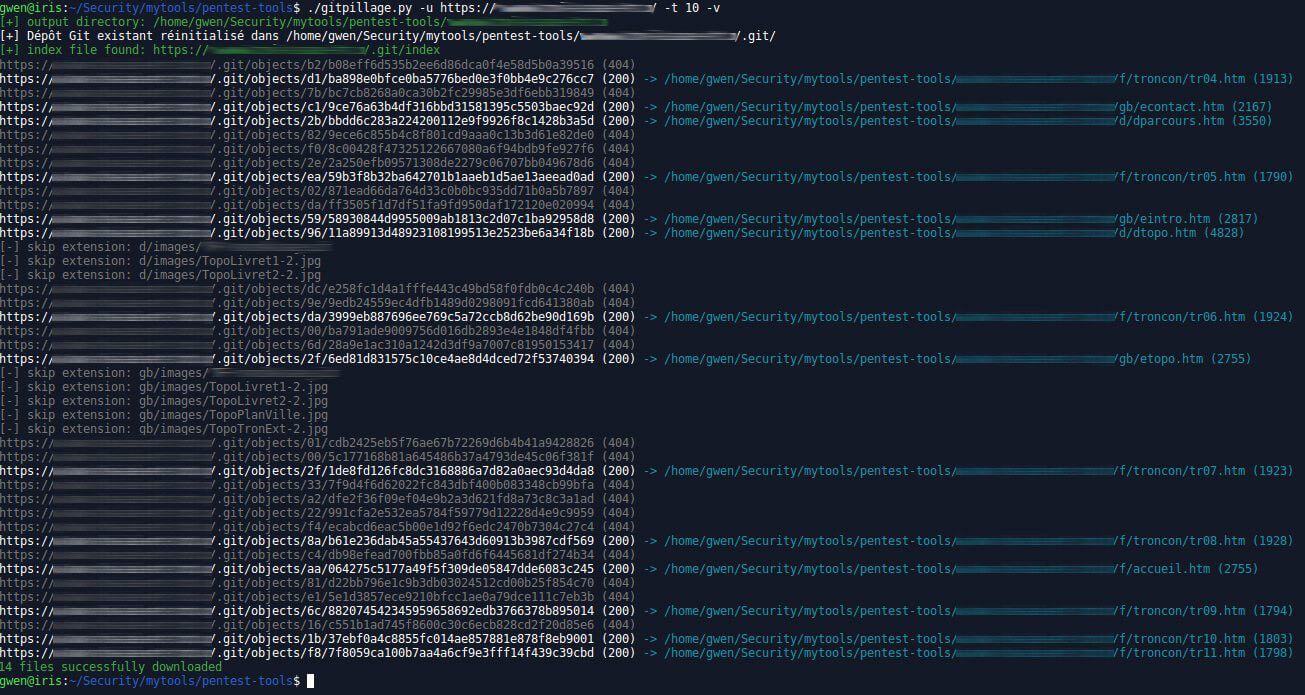
git-pillage.py
Inspired by gitpillage.sh. I wanted to make it faster and more verbose, it was also a nice way to pratice that exercise on Pentesterlab about Git directory structure.
usage: git-pillage.py [-h] [-u URL] [-t THREADS] [-e EXTENSION] [-x EXCLUDE]
[-v]
optional arguments:
-h, --help show this help message and exit
-u URL, --url URL url of the .git, but without the .git directory
-t THREADS, --threads THREADS
threads, default: 5
-e EXTENSION, --extension EXTENSION
extensions to download separated by comma, overwrite
--exclude, default: all but default exclude
-x EXCLUDE, --exclude EXCLUDE
extensions to exclude separated by comma, default: png
,gif,jpg,jpeg,ico,svg,eot,otf,ttf,woff,woff2,css,less,
po,mo,mp3,mp4,mpeg,avi
-v, --verbose verbose mode, default: off
Examples:
git-pillage.py -u https://www.example.com -t 10 -v
git-pillage.py -u https://www.example.com/ -x pdf,doc,docx,txt,xls,xlsx
git-pillage.py -u https://www.example.com/htdocs/src/ -t 10 -e php,sh,py,rb,bat -v
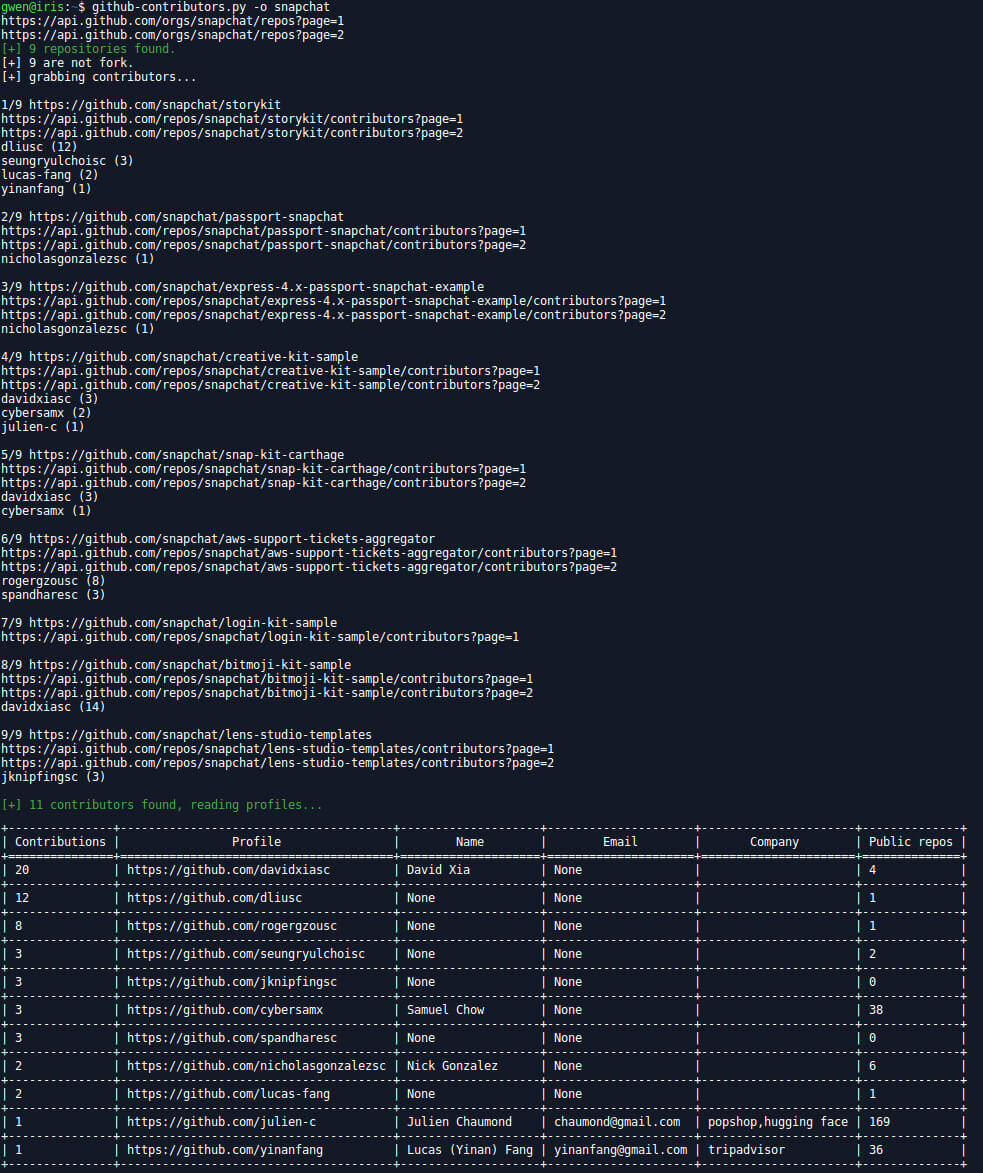
github-contributors.py
This script returns some informations about the peoples listed as contributors of every repositories of an organization.
usage: github-contributors.py [-h] [-t TOKEN] [-o ORG] [-u USER]
optional arguments:
-h, --help show this help message and exit
-t TOKEN, --token TOKEN
auth token
-o ORG, --org ORG organization
-u USER, --user USER user
Example:
git-contributors.py -o snapchat
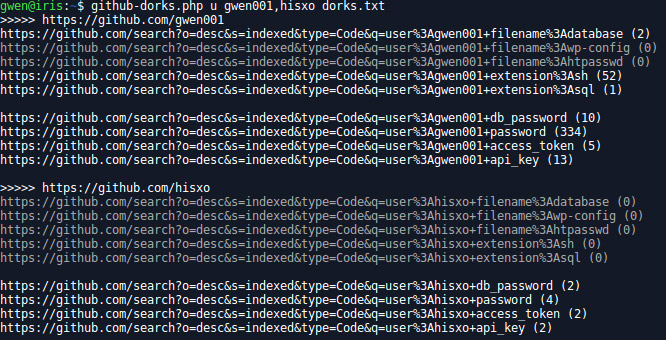
github-dorks.php
Performs dorks on GitHub for the users/organizations provided (list can be provided by separating users/orgs with comma). Dorks must be listed in a single text file. Results are not stored (could be an option?), only the number or results is displayed.
Usage: /opt/bin/github-dorks.php <o/u/n> <org/user> [<dork file>]
github-dorks.py
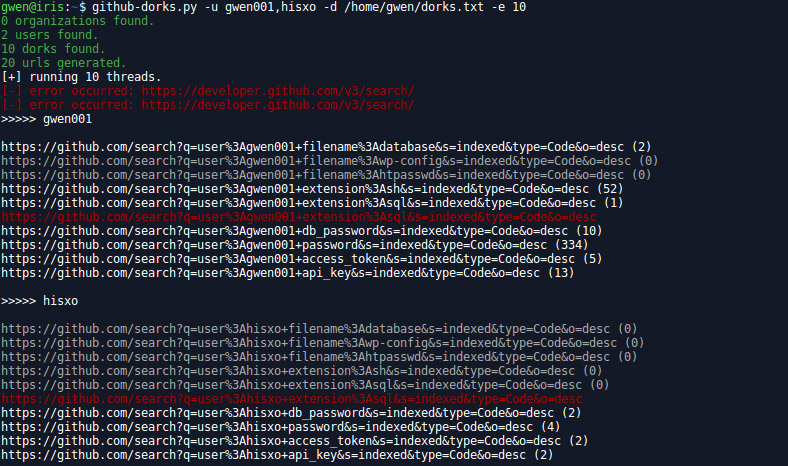
The Python version of the previous script. It’s supposed to be much faster (and more stable) because of the multi thread option, but unfortunately GitHub rate limit on search code is pretty low so use it carefully.
usage: github-dorks.py [-h] [-d DORKS] [-t TOKEN] [-o ORG] [-e THREADS]
[-u USER]
optional arguments:
-h, --help show this help message and exit
-d DORKS, --dorks DORKS
dorks file
-t TOKEN, --token TOKEN
auth token
-o ORG, --org ORG organization
-e THREADS, --threads THREADS
maximum n threads
-u USER, --user USER user
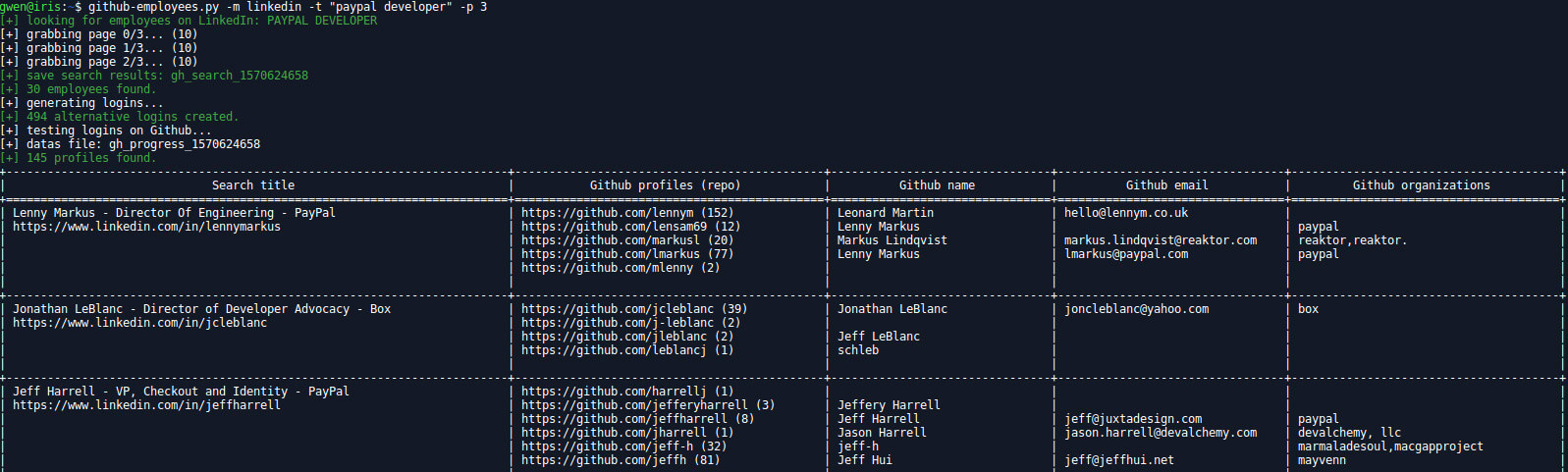
github-employees.py
(try to) Find GitHub account of employees of a company through Google search and displays some basics informations about them.
2 mods are available for now:
- github, Google dork is:
site:github.com [term], nicknames are the ones returned - linkedin, Google dork is:
site:linkedin.com/in [term], nicknames are generated by the script using firstname and lastname
Since the script uses the magnificient Goop from s0md3v, a facebook cookie is required to bypass Google rate limit (can be provided on the command line or environment variable).
usage: github-employees.py [-h] [-m MOD] [-s STARTPAGE] [-f FBCOOKIE]
[-t TERM] [-p PAGE] [-r RESUME] [-i INPUT]
[-k KEYWORD] [-o TOKEN]
optional arguments:
-h, --help show this help message and exit
-m MOD, --mod MOD module to use to search employees on google,
available: linkedin, github, default: github
-s STARTPAGE, --startpage STARTPAGE
search start page, default 0
-f FBCOOKIE, --fbcookie FBCOOKIE
your facebook cookie (or set env var FACEBOOK_COOKIE)
-t TERM, --term TERM term (usually company name)
-p PAGE, --page PAGE n page to grab, default 10
-r RESUME, --resume RESUME
resume previous session
-i INPUT, --input INPUT
input datas source saved from previous search
-k KEYWORD, --keyword KEYWORD
github keyword to search
-o TOKEN, --token TOKEN
github token
Examples:
github-employees.py -m github -p 30 -t "valvesoftware"
github-employees.py -f "fr=1dQvI2Lp7cTfjt; datr=6uqdXS6tsFY5CJ..." -m linkedin -o "1ec46a7..." -t "valvesoftware programmer" -t "valvesoftware admin"
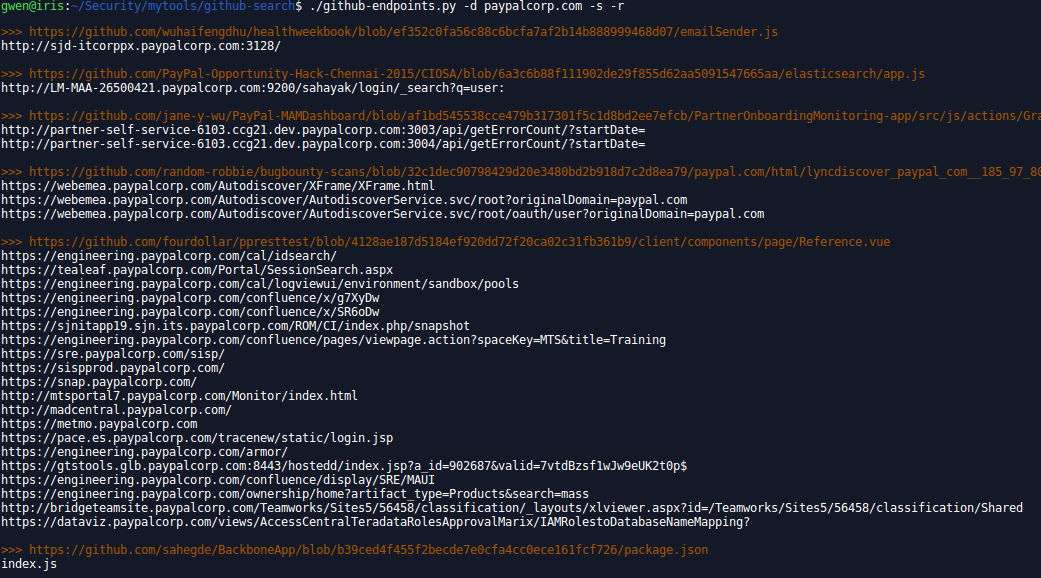
github-endpoints.py
Improve you recon by searching endpoints on GitHub. Very useful, you can also get some extras subdomains. Relative urls can be displayed or not as well as external domains urls. Based on regexp, it also has an exclude list. Feed it as much as you can to filter the results the way you like!
usage: github-endpoints.py [-h] [-t TOKEN] [-d DOMAIN] [-e] [-a] [-r] [-s]
optional arguments:
-h, --help show this help message and exit
-t TOKEN, --token TOKEN
auth token (required)
-d DOMAIN, --domain DOMAIN
domain you are looking for (required)
-e, --extend also look for <dummy>example.com
-a, --all displays urls of all other domains
-r, --relative also displays relative urls
-s, --source display urls where endpoints are found
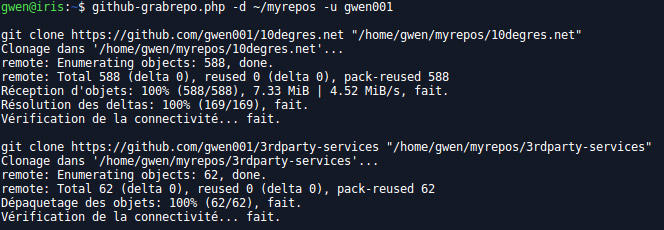
github-grabrepo.php
Very simple script that clones all public repositories belonging to a given user/organization.
Usage: php github-grabrepo.php -o/-u <organization/user> [OPTIONS]
Options:
-d set destination directory (required)
-o set organization (org or user required)
-u set user (org or user required)
-f grab forked repositories as well
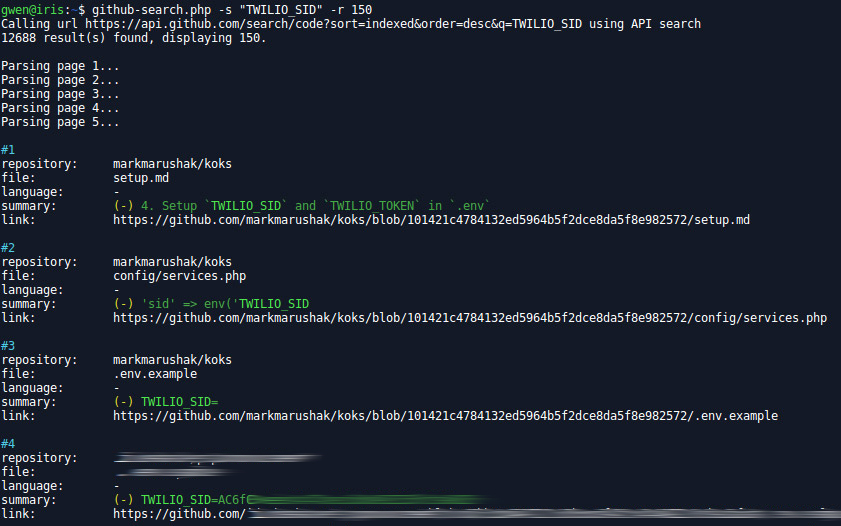
github-search.php
Perform code search through GitHub API.
Usage: php github-search.php [OPTIONS]
Options:
-c set cookie session
-e file extension filter
-f looking for file
-h print this help
-l language filter
-m look for commit, -o and -p are required
-n no color
-p provide repository name
-o provide organization name
-r maximum number of results, default 100
-s search string
-t set authorization token (overwrite cookie, best option)
Examples:
php github-search.php -o myorganization -s db_password
php github-search.php -o myorganization -f wp-config.php -s db_password
php github-search.php -c "user_session=B0KqycP8LlYORc-s3WFZoH71TG" -f wp-config -e php -r 1000
php github-search.php -t 32a11e6f340c2fe1a6071795a3b1a8c876b3cf29 -l php -s DB_USERNAME
php github-search.php -s "DB_USERNAME filename:wp-config extension:php" -n
github-secrets.py
Find secrets deployed on GitHub.
usage: github-secrets.py [-h] [-t TOKEN] [-s SEARCH] [-e] [-r REGEXP] [-u] [-v]
options:
-h, --help show this help message and exit
-t TOKEN, --token TOKEN
your github token (required)
-s SEARCH, --search SEARCH
search term you are looking for (required)
-e, --extend also look for <dummy>example.com
-r REGEXP, --regexp REGEXP
regexp to search, default is SecLists secret-keywords list (can be a tomnomnom gf file)
-u, --url display only url
-v, --verbose verbose mode, for debugging purpose
Examples:
python3 github-secrets.py -s "AWS_KEY filename:.env" -r "AKIA[A-Z0-9]{16}"
python3 github-secrets.py -s "DB_PASSWORD filename:wp-config.php" -r "DB_PASSWORD',\s*'[^']{4,}"

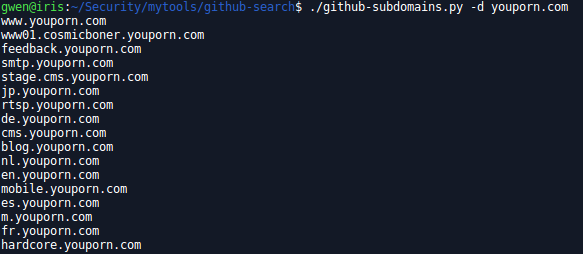
github-subdomains.py
Find additional subdomains on GitHub. Very useful during you recon phase, you will probably get some extras subdomains other tools didn’t find because not public.
usage: github-subdomains.py [-h] [-t TOKEN] [-d DOMAIN] [-e] [-s]
optional arguments:
-h, --help show this help message and exit
-t TOKEN, --token TOKEN
auth token (required)
-d DOMAIN, --domain DOMAIN
domain you are looking for (required)
-e, --extend also look for <dummy>example.com
-s, --source display first url where subdomains are found
github-survey/index.php
Web page that displays GitHub search results of dorks set in a config file github-survey.json located in the same directory.
This file also contains an exclude list, so results considered as useless are skipped.
The exclude list is feeded through buttons in that same page.
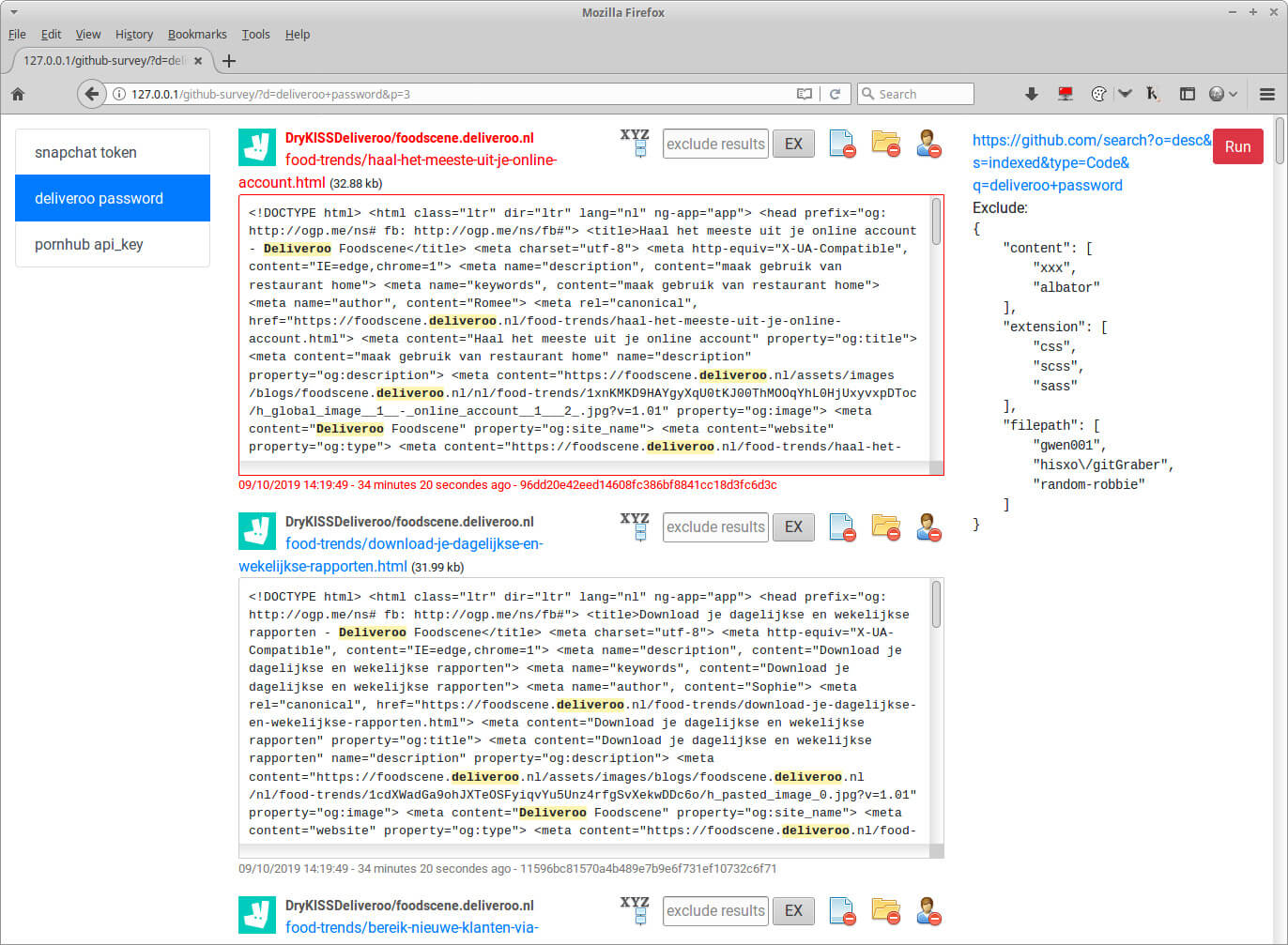
It’s also possible to mark a file, so his sha is set as the last-sha parameter in the config file (and later highlighted in red).
This is very useful when combined with the next Python script.
github-survey.py
The first version of my GitHub survey script.
It performs GitHub search using the same config file mentionned above but does not exclude anything.
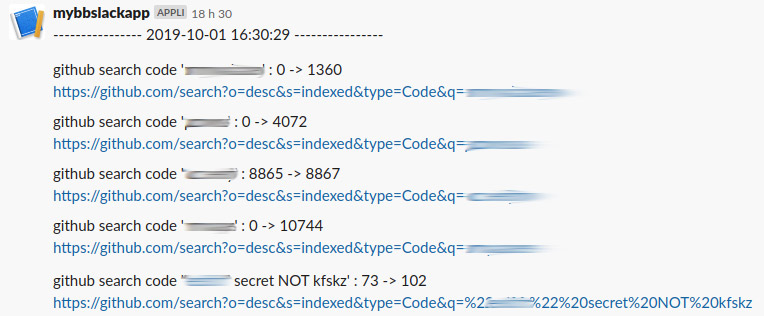
An alert is sent to a Slack channel if the total_count is superior to the total_count of the previous run (it’s crontabed).
github-survey2.py
Unfortunately I understood later that GitHub API is not so reliable. If you perform several searches in a row (same dork), using the API or the website, you’ll notice that the results counter varies. Because of that I got many many (too many) notifications on my Slack, mostly false positive.
According to this I wrote a second version of GitHub survey which is much more reliable.
First it uses the last-sha parameter to limit the search (search until…) then it filters the results with the exclude list feeded by the web page to decide if a notification should be send or not. Much better!
usage: github-survey2.py [-h] [-t TOKEN] [-p PAGE] [-c CONFIG]
optional arguments:
-h, --help show this help message and exit
-t TOKEN, --token TOKEN
auth token
-p PAGE, --page PAGE n max page
-c CONFIG, --config CONFIG
config file, default: ~/.config/github-survey.json

github-users.py
This script performs a user search using GitHub API and display some informations about them.
usage: github-users.py [-h] [-t TOKEN] [-k KEYWORD]
optional arguments:
-h, --help show this help message and exit
-t TOKEN, --token TOKEN
auth token
-k KEYWORD, --keyword KEYWORD
keyword to search

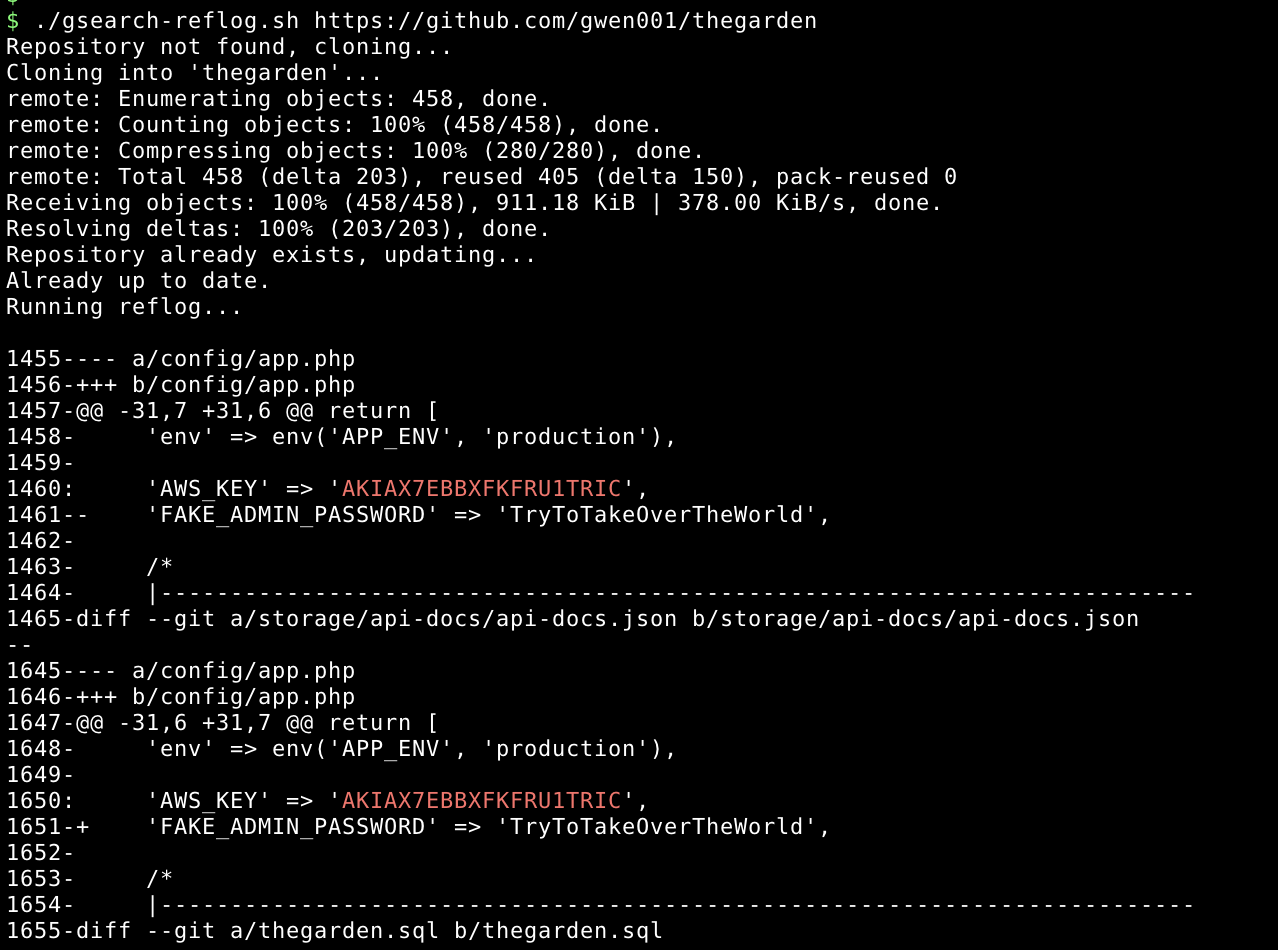
gsearch-reflog.sh
This script downloads a given repository and performs searches in his logs in order to find secrets.
Usage: ./gsearch-reflog.sh <repository url>
Conclusion
You would probably think that all those scripts are useless. There is already so many tools to perform history search, secret discovery and so on… The main reason of all of this was to learn Python, it was part of my goal in 2019. I can now say that I am confortable with the basics, even if most of the code above is horrible (please, don’t judge, after syntax learning comes code organization).
I am not very familiar with GitHub issues (understand “it won’t be fixed soon”) so feel free to use those programs or not, fully rewrite them or partially or copy or update or whatever :)